1.在Halo数据库中
字符串:使用单引号(‘’)引用
select ‘halo’;
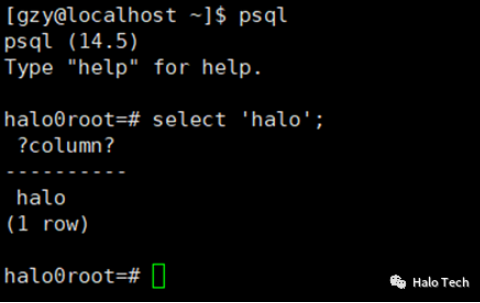
标识符:可以直接引用,也可使用双引号(“”)引用
select id from test;
select “id” from “test”;
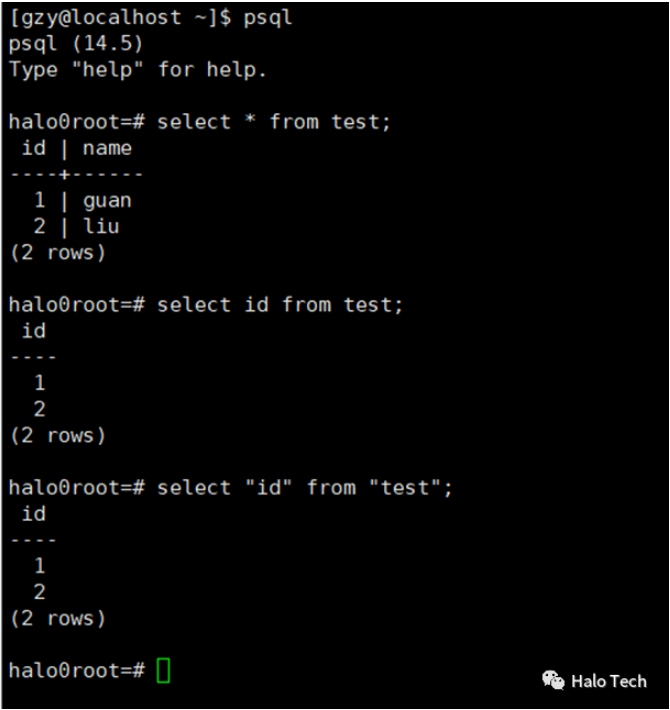 其中,使用双引号引用的标识符可以包含一些特殊字符,可以是关键字,并且区分大小写
其中,使用双引号引用的标识符可以包含一些特殊字符,可以是关键字,并且区分大小写
2.在Mysql数据库中
字符串:使用单引号(‘’)或双引号(“”)引用,两者功能相同
select ‘halo’;
或select “halo”;
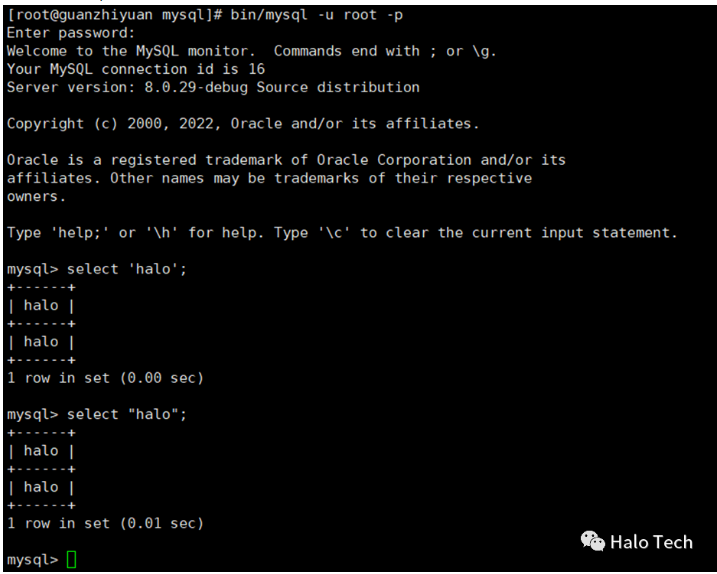 其中,使用反引号引用的标识符可以包含一些特殊字符,可以是关键字,默认不区分大小写
其中,使用反引号引用的标识符可以包含一些特殊字符,可以是关键字,默认不区分大小写
3.具体实现
在Halo数据库的语法文件中,字符串、标识符的记号(Token)分别为Sconst、Ident,在词法文件中,具体修改如下:
第一步,添加反引号标识符识别规则,如下:
{xbtstart} { SET_YYLLOC(); BEGIN(xbt); startlit(); }<xbt>{xbtstop} { char *ident; BEGIN(INITIAL); if (yyextra->literallen == 0) yyerror("zero-length delimited identifier"); // ident = litbufdup(yyscanner); // if (yyextra->literallen >= NAMEDATALEN) // truncate_identifier(ident, yyextra->literallen, true); ident = downcase_truncate_identifier(yyextra->literalbuf, yyextra->literallen, true); yylval->str = ident; return IDENT; }<xbt>{xbtdouble} { addlitchar('`', yyscanner); }<xbt>{xbtinside} { addlit(yytext, yyleng, yyscanner); }<xbt><<EOF>> { yyerror("unterminated backtick identifier"); }第二步,删除单引号字符串的部分规则(如对字符串中八进制,十六进制进行转义),如下:
<xe>{xeoctesc} { unsigned char c = strtoul(yytext + 1, NULL, 8); check_escape_warning(yyscanner); addlitchar(c, yyscanner); if (c == '\0' || IS_HIGHBIT_SET(c)) yyextra->saw_non_ascii = true; }<xe>{xehexesc} { unsigned char c = strtoul(yytext + 2, NULL, 16); check_escape_warning(yyscanner); addlitchar(c, yyscanner); if (c == '\0' || IS_HIGHBIT_SET(c)) yyextra->saw_non_ascii = true; }第三步,删除与双引号有关的标识符识别规则,添加双引号字符串识别规则,结果如下:
{xdqstart} { yyextra->warn_on_first_escape = false; yyextra->saw_non_ascii = false; SET_YYLLOC(); // if (yyextra->standard_conforming_strings) // BEGIN(xdq); // else // BEGIN(xde); BEGIN(xde); startlit(); }<xdq,xde>{dquote} { /* * When we are scanning a quoted string and see an end * quote, we must look ahead for a possible continuation. * If we don't see one, we know the end quote was in fact * the end of the string. To reduce the lexer table size, * we use a single "xqs" state to do the lookahead for all * types of strings. */ yyextra->state_before_str_stop = YYSTATE; BEGIN(xdqs); }<xdqs>{dquotecontinue} { /* * Found a quote continuation, so return to the in-quote * state and continue scanning the literal. Nothing is * added to the literal's contents. */ BEGIN(yyextra->state_before_str_stop); }<xdqs>{dquotecontinuefail} |<xdqs>{other} |<xdqs><<EOF>> { /* * Failed to see a quote continuation. Throw back * everything after the end quote, and handle the string * according to the state we were in previously. */ yyless(0); BEGIN(INITIAL); switch (yyextra->state_before_str_stop) { case xdq: case xde: /* * Check that the data remains valid, if it might * have been made invalid by unescaping any chars. */ if (yyextra->saw_non_ascii) pg_verifymbstr(yyextra->literalbuf, yyextra->literallen, false); yylval->str = litbufdup(yyscanner); return SCONST; default: yyerror("unhandled previous state in xdqs"); } }<xdq,xde>{xdqdouble} { addlitchar('\"', yyscanner); }<xdq>{xdqinside} { addlit(yytext, yyleng, yyscanner); }<xde>{xdeinside} { addlit(yytext, yyleng, yyscanner); }<xde>{xdeescape} { if (yytext[1] == '\"') { if (yyextra->backslash_quote == BACKSLASH_QUOTE_OFF || (yyextra->backslash_quote == BACKSLASH_QUOTE_SAFE_ENCODING && PG_ENCODING_IS_CLIENT_ONLY(pg_get_client_encoding()))) ereport(ERROR, (errcode(ERRCODE_NONSTANDARD_USE_OF_ESCAPE_CHARACTER), errmsg("unsafe use of \\\" in a string literal"), errhint("Use \"\" to write double quotes in strings. \\\" is insecure in client-only encodings."), lexer_errposition())); } if(yytext[1] == '0') yytext[1] = '\0'; check_string_escape_warning(yytext[1], yyscanner); addlitchar(unescape_single_char(yytext[1], yyscanner), yyscanner); }<xde>. { /* This is only needed for \ just before EOF */ addlitchar(yytext[0], yyscanner); }<xdq,xde><<EOF>> { yyerror("unterminated double quoted string"); }4.结果展示
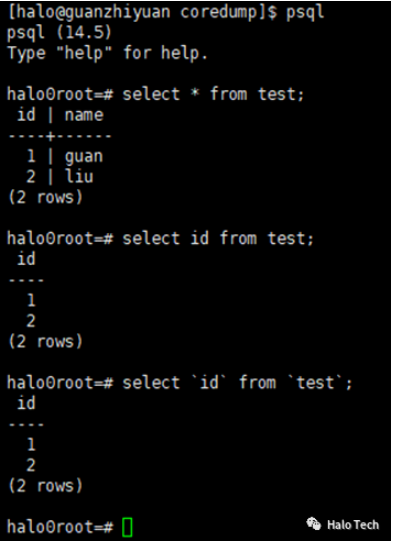
字符串:
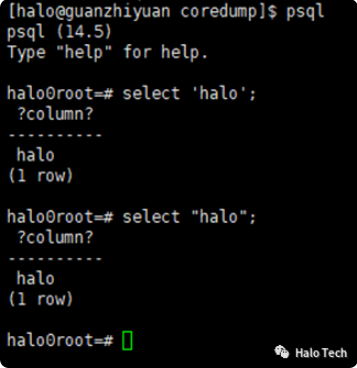
标识符:

人物A 回复
这是回复
人物B 回复
我回复你了
人物A 回复
回复已收到